
For the past two decades, software development has been defined by web and mobile stacks. Acronyms like LAMP (Linux, Apache, MySQL, PHP) or MERN (MongoDB, Express, React, Node.js) dictated how developers-built applications. Today, the fundamental paradigm shift is underway. Software is no longer just executing deterministic, hard-coded rules; it is reasoning, generating, and understanding.
This shift requires an entirely new architecture for The Modern AI Stack 2026.
Understanding how modern AI systems are built is no longer just a niche requirement for machine learning engineers. For developers, it is the new blueprint for application design. For businesses, it is the critical infrastructure required to turn proprietary data into a competitive moat. For content creators and product managers, mastering the full stack is essential for understanding what is technically feasible, where bottlenecks lie, and how to design end-user experiences that feel magical rather than frustrating.
If you want to understand how the most advanced applications of 2026 operate under the hood, you need to understand the AI stack. Let’s break it down layer by layer.
What Is the AI Stack?
The AI stack is the layered architecture that powers modern artificial intelligence applications. Just as traditional computing stacks separate the operating system from the database and the frontend interface, the AI stack compartmentalizes the complex processes required to build, host, query, and manage AI models.
Modern enterprise architecture demands a “model agnostic” approach. Instead of relying entirely on a single proprietary vendor company, organizations are now building modular AI stacks where models can be swapped out, retrieval pipelines upgraded, and infrastructure optimisation without rebuilding the entire application.
At the bottom layer of AI stack there are massive arrays of silicon churn through calculations. At the middle layers there are complex data pipelines, reasoning engines and agents aim to provide the AI with context and memory. At the top layer, end-user applications translate these massive computational feats into intuitive conversational interfaces and automated workflows.
Layer 1: Infrastructure (The Heavy Metal)
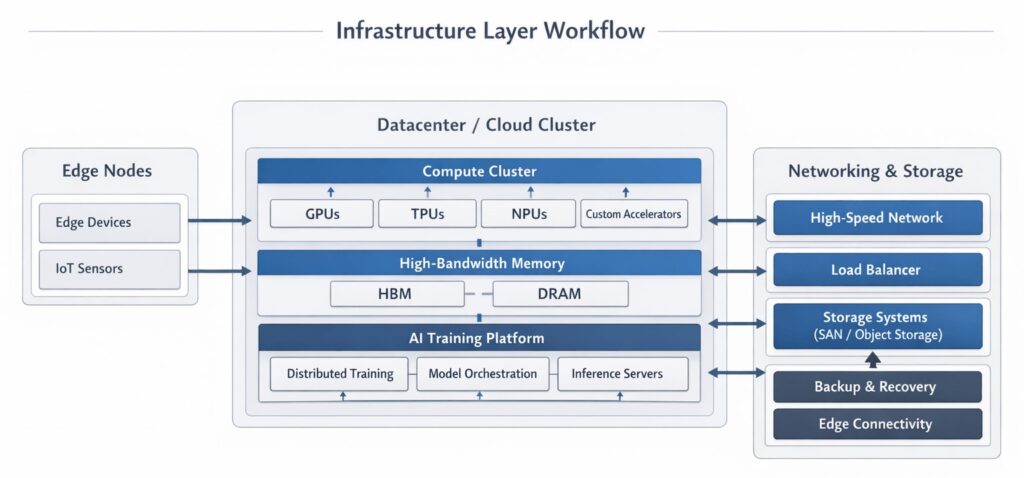
- The infrastructure layer is the physical and virtualized hardware that provides the massive computational power required to train models and serve predictions (inference). Without highly specialized infrastructure, modern AI simply cannot exist.
- Cloud Computing Platforms: The hyperscale AWS, Google Cloud, and Microsoft Azure are the primary landlords of the AI boom, providing highly available, scalable environments.
- GPUs and Specialized AI Hardware: Central Processing Units (CPUs) are designed for sequential processing and are too slow for deep neural networks, which require millions of simultaneous matrix multiplications.
- High-Density GPUs: NVIDIA’s architectures (like Hopper and the newer Blackwell chips) dominate the space.
- Custom Silicon (ASICs): The industry is aggressively moving toward custom inference chips. Google’s Tensor Processing Units (TPUs), AWS Trainium/Inferentia, and Groq’s Language Processing Units (LPUs) are purpose-built to accelerate AI workloads with incredible speed and cost-efficiency.
- Private Enterprise AI Stacks: In 2026, data sovereignty is paramount. Industries like finance, healthcare, and defense cannot send sensitive data to public cloud AI services. This has given rise to enterprise-grade on-premises cloud platforms (like Alibaba Cloud’s AI Stack), utilizing high-density GPU clusters, high-speed InfiniBand networking, and completely air-gapped secure environments.
- Storage and Networking: Moving petabytes of data into GPUs fast enough to keep them fed requires ultra-fast NVMe storage and specialized networking protocols (like RoCE) to ensure clusters of tens of thousands of GPUs can communicate in microseconds.
- Why it matters: If your infrastructure is bottlenecked, model training takes months instead of days, and your user-facing applications suffer from high latency (slow response times), destroying the user experience.
Layer 2: Foundation Models (The Cognitive Core)
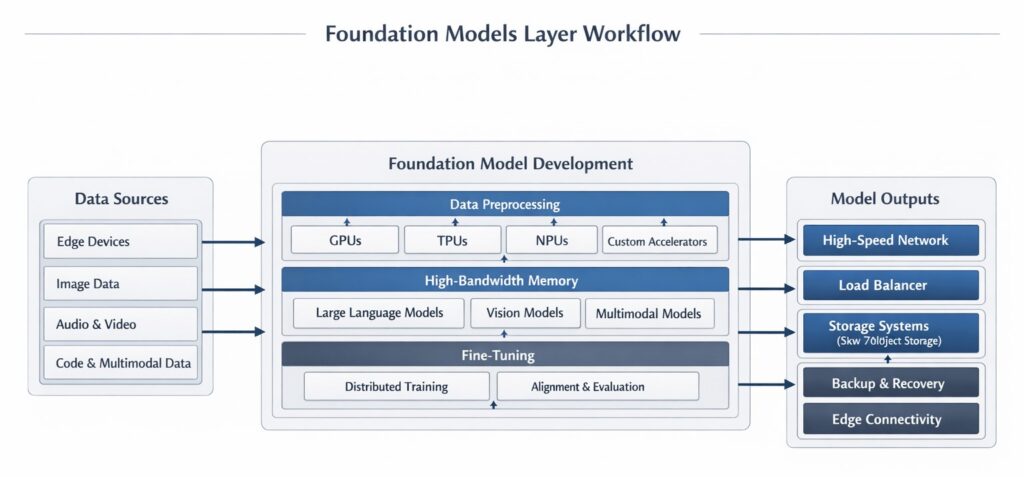
- Sitting directly above the physical infrastructure are the foundation models. These are massive, general-purpose neural networks trained on vast amounts of unlabeled data.
- Large Language Models (LLMs): These models, such as OpenAI’s GPT-4 series or Anthropic’s Claude 3.5 family, are built on the Transformer architecture to understand, predict, and generate human text.
- Multimodal Models: The cutting edge has moved beyond text. Native multimodal models, like Google’s Gemini, process text, code, images, audio, and video simultaneously. They can “watch” a video and answer questions about specific frames without relying on separate transcription tools.
- Small Language Models (SLMs): As efficiency becomes critical, highly capable SLMs (under 10 billion parameters) like Microsoft’s Phi-3 or Meta’s Llama 3 8B are being deployed for narrow, specific tasks, significantly reducing compute costs.
Open-Weights vs Proprietary Models:
- Proprietary (Closed): These models (e.g., GPT-4, Claude 3.5) are hosted and maintained by their creators. Access is limited to API calls, meaning you don’t own the weights, but you benefit from their massive scale and constant updates—at the price of potential data privacy trade-offs and API costs.
- Open-tools: Models like Llama 3, Mistral, and Gemma democratize AI by making their internal weights public. This allow private hosting, removes third-party dependencies and allows for specialized optimization that isn’t possible with a locked API.
Layer 3: Model Access and APIs (The Bridge)
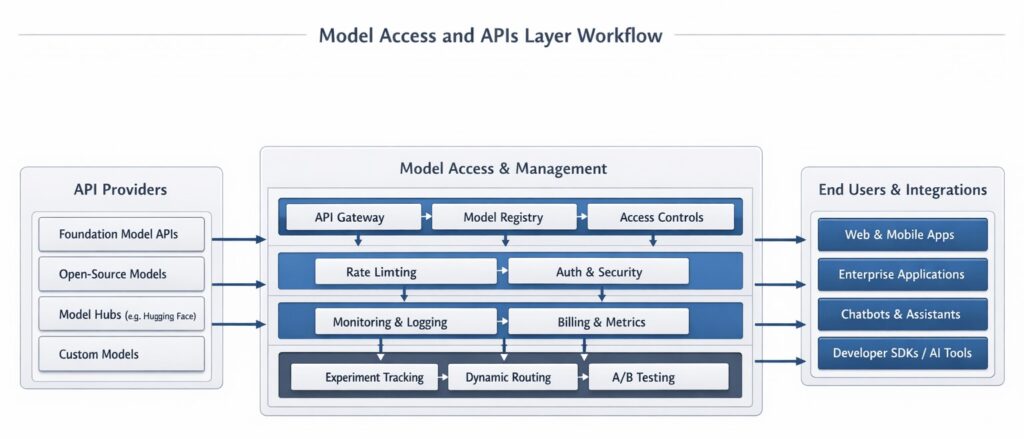
- Layer 3: The Inference Gateway: Think of this as the API bridge for your AI stack. While proprietary models use their own APIs, open-weight models require a specialized host. Leading inference providers—including Groq, Together AI, and DeepInfra—have revolutionized this layer. By using dedicated AI accelerators instead of standard GPUs, they serve models like Llama 4 at “human-speed” (hundreds of tokens per second) for a fraction of the cost of legacy cloud providers.
- Fine-Tuning and Customization: Foundation models are generalists. To make them specialists (e.g., teaching a model to speak in a specific brand voice or understand legal jargon), developers use fine-tuning. Techniques like LoRA (Low-Rank Adaptation) allow developers to tweak behavior efficiently without retraining the entire massive network from scratch.
- Model-as-a-Service (MaaS): Many enterprise stacks now abstract the model layer entirely, providing an internal MaaS API where developers can call different models based on their need (e.g., routing simple tasks to an SLM to save money, and complex reasoning to a massive frontier model).
Layer 4: Data Layer (The Memory Foundation)
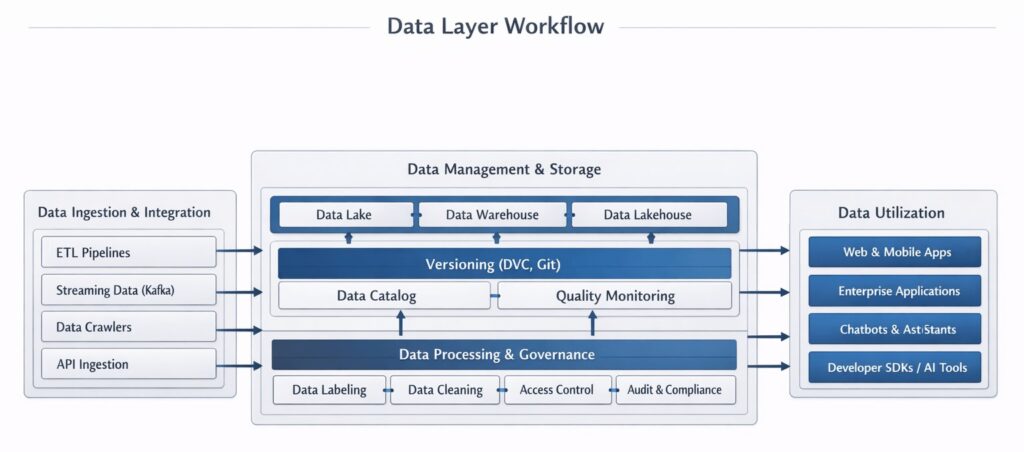
- An AI model is only as intelligent as the context it is given. The data layer is responsible for preparing proprietary data so the AI can understand and utilize it.
- Structured and Unstructured Data: Structured data lives in neat tables (SQL databases). Unstructured data—which makes up over 80% of enterprise knowledge—includes PDFs, Slack messages, videos, and Word documents.
- Data Pipelines and ETL: Data doesn’t prepare itself. ETL (Extract, Transform, Load) pipelines act as continuous delivery engines—pulling raw information from sources like Salesforce and company wikis, cleaning up messy formatting, and transforming it into a structured format ready for AI.
- Vector Embeddings: To apply semantic search, text must be mapped into a computational format. Embedding models convert sentences into vectors (multi-dimensional numerical arrays) that encode their contextual meaning. Within this geometric space, terms that are semantically similar are mathematically positioned near one another and are called vector embeddings.
- Vector Databases: Traditional databases search for exact keyword matches. Vector databases—like Pinecone, Milvus, Weaviate, or Qdrant—are purpose-built to store these mathematical embeddings and perform incredibly fast nearest-neighbor similarity searches.
Layer 5: Retrieval Layer (Advanced RAG)
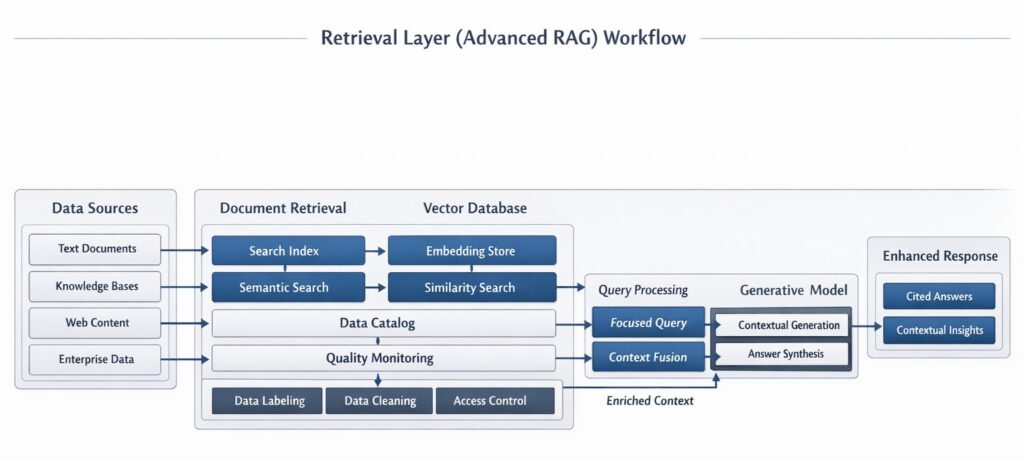
- Large Language Models have a fundamental flaw: their knowledge is frozen at the time they were trained, and they lack access to your private data. Retrieval-Augmented Generation (RAG) solves this by fetching relevant data from your databases and inserting it into the AI’s prompt before it answers.
- By 2026, simple “naive RAG” has been replaced by highly sophisticated Advanced RAG architectures designed to eliminate hallucinations and handle complex enterprise reasoning.
- Key Advanced RAG Techniques:
- Semantic Chunking & Overlap: modern chunking respects sentence boundaries and maintains contextual overlap and prevents the AI from suffering “context fragmentation.” Instead of arbitrarily cutting documents every 500 words.
- Hybrid Search: Relying purely on vector search (semantic similarity) can miss exact keywords (like a specific product serial number). Hybrid search combines dense vector retrieval with traditional sparse keyword search (like BM25) for comprehensive coverage.
- Cross-Encoder Re-Ranking: Vector search might return 50 loosely related documents. A re-ranking layer uses a specialized model (like Cohere Rerank) to deeply analyze those 50 results against the user’s specific query, bubbling the absolute top 3 most relevant chunks to the surface.
- Graph RAG: Traditional RAG suffers from “connection blindness,” struggling to connect disparate dots. Graph RAG structures knowledge as an interconnected Knowledge Graph (entities and relationships), allowing the AI to understand complex, multi-layered queries like “How do our climate policies affect our tier-2 supply chains?”
- Fusion Retrieval: Generating multiple slightly varied versions of the user’s query, running searches for all of them, and fusing the results to ensure no relevant context is missed.
Layer 6: Orchestration Frameworks (The Conductor)
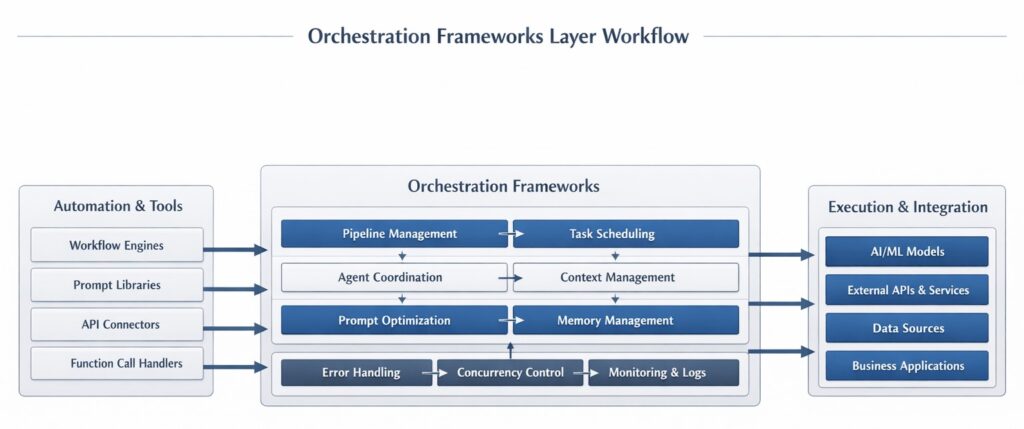
Building an AI application involves chaining together multiple prompts, integrating external tools (like web browsers or calculators), managing conversation memory, and routing tasks. This requires orchestration.
- LangChain: The ubiquitous framework providing standardized, modular components for connecting LLMs to data sources, creating multi-step prompt chains, and managing memory.
- LlamaIndex: Originally designed to optimize the RAG pipeline, LlamaIndex excels at connecting LLMs to complex, varied data sources, providing advanced tools for document parsing and indexing.
- Workflow Orchestration and Tool Calling: Modern orchestration isn’t just about text generation; it’s about action. Orchestrators intercept a user request, recognize that the LLM needs external data, trigger a third-party API, retrieve the result, and feed it back to the LLM.
Layer 7: Agent Frameworks (Autonomous Teams)
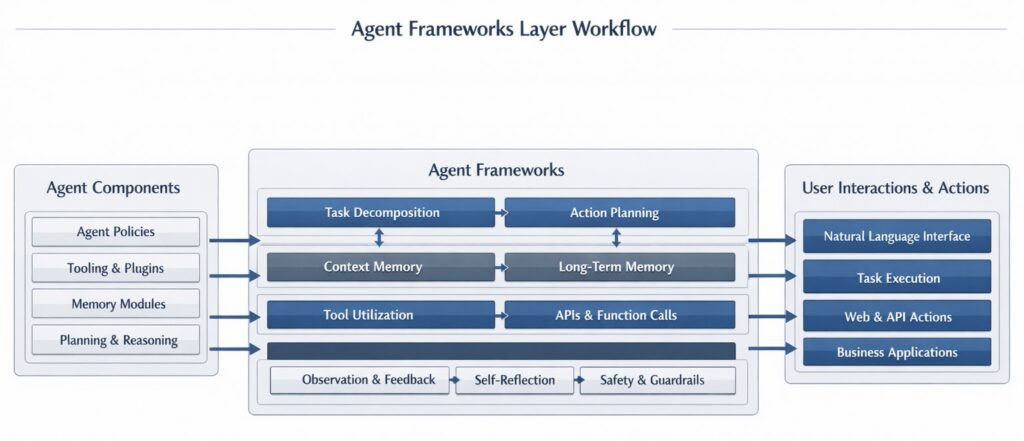
While orchestrators follow rigid pipelines, Agents represent the shift toward autonomous AI. In an agentic framework, the AI is given a goal, a set of tools, and the autonomy to plan, loop, and iterate.
In 2026, several distinct agent frameworks dominate the landscape based on specific use cases:
- LangGraph (Best for Production): Built by the LangChain team, LangGraph models agents as explicit state machines (nodes and edges). It gives developers precise control over branching logic, human-in-the-loop approvals, and stateful workflows. It is the gold standard for robust, customer-facing applications.
- CrewAI (Best for Fast Prototyping): A role-based multi-agent framework. You define a “crew” of agents (e.g., a “Researcher,” a “Writer,” and a “Reviewer”), assign them a master task, and CrewAI handles their collaboration and delegation automatically.
- AutoGen / AG2 (Best for Research & Code): Pioneered by Microsoft Research, AutoGen models agents as participants in a group chat. They debate, review each other’s code, and iterate on complex problem-solving.
- Microsoft Semantic Kernel (Best for Enterprise): Designed heavily for the .NET/C# ecosystem and Azure integration, mapping cleanly to strict enterprise governance models.
- Pydantic AI (Best for Developers): Offers incredibly strong type-safe execution for Python developers, ensuring reliable, structured data outputs from agents.
Layer 8: Application Layer (The Interface)
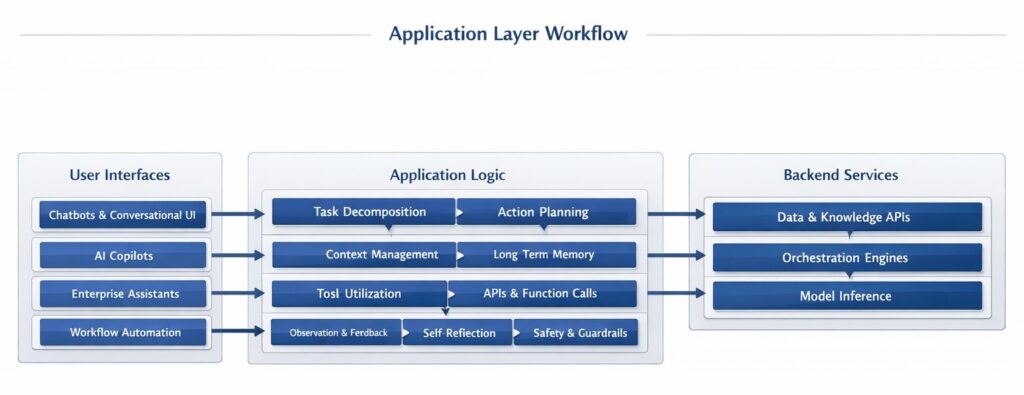
The application layer is the tip of the iceberg—the interface where human beings interact with the complex machinery operating beneath them.
- Chatbots: Conversational UIs optimized for open-ended Q&A and basic task assistance.
- Copilots: Context-aware assistants embedded directly into existing software (e.g., GitHub Copilot for code, or Microsoft 365 Copilot for spreadsheets). They assist with the creation of the specific artifact the user is working on.
- Enterprise Assistants: Internal search engines connected via Advanced RAG to a company’s secure intranets, HR policies, and CRMs.
- Workflow Automation: “Invisible AI” operating under the hood, such as customer support platforms that autonomously categorize tickets, draft responses, and process refunds without human intervention.
Layer 9: Evaluation, Security, and Observability
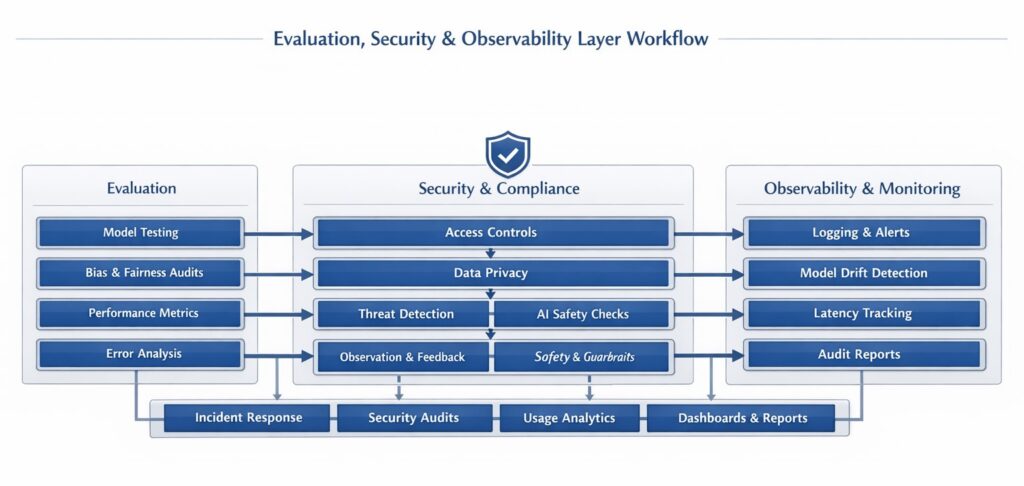
Because AI models are probabilistic (generating answers based on statistical likelihood), they cannot be tested or monitored using traditional deterministic software engineering methods. This has created an entirely new layer dedicated to trust and visibility.
1. AI Observability & FinOps
Traditional monitoring tools look at server uptime. AI observability tools (like TrueFoundry, LangSmith, or Datadog LLM) look at AI logic.
- Deep Tracing: Visualizing multi-step agent executions to understand exactly where a hallucination occurred or why an agent got stuck in an infinite loop.
- Token-Level Cost Attribution (FinOps): AI is expensive. Modern observability platforms attribute LLM spend by team, application, or specific agent, enforcing strict budgets and rate limits in real-time.
2. Guardrails and Governance
Ensuring the model doesn’t say something inappropriate, leak secure data, or go off-brand.
- Active Filtering: Tools like AWS Bedrock Guardrails, NVIDIA NeMo Guardrails, or Virtana sit between the user and the model. They actively filter incoming prompts to block jailbreaks, mask Personally Identifiable Information (PII), and enforce denied topics before the LLM ever sees the query.
- Compliance: Ensuring RAG pipelines respect strict Document-Level Access Controls (so a junior employee cannot query an AI and retrieve the CEO’s private strategy documents).
3. Evaluation (LLM-as-a-Judge)
How do you automatically test an AI that answers the same question slightly differently every time? Developers use frameworks like Ragas or TruLens to evaluate outputs mathematically: Is the answer faithful to the source of text? Is it relevant to the prompt? Often, a larger, smarter model (like GPT-4) is automated to act as a “judge,” grading the outputs of smaller application models against strict rubrics.
How the Full AI Stack Works Together: A Step-by-Step Walkthrough
To understand the synergy, let’s trace a real-world query. An employee asks an internal Enterprise Agent: “What is our policy on remote work for the engineering team?”
- Application Layer: The employee types the question into their corporate chat interface.
- Orchestration Layer: A framework (like LangGraph) intercepts the request and determines it needs to trigger a retrieval tool.
- Data & RAG Layer:
- The user’s text is converted into a vector by an Embedding Model.
- The Vector Database performs a hybrid search across millions of company documents.
- A Cross-Encoder Reranker takes the top 20 results and distills them down to the 3 most strictly relevant paragraphs.
- Foundation Model Layer: The orchestrator compiles a hidden system prompt containing the retrieved context and sends it to an open-weights model like Llama 3 hosted on a private Inference API.
- Infrastructure Layer: Deep in an on-premises data center, High-Density GPUs process the matrix multiplications.
- Observability & Guardrail Layer: The generated response is checked by a Guardrail to ensure no secure salary data was accidentally retrieved, while the Observability tool logs the exact token cost to the engineering department’s budget.
- Application Layer: The text is rendered beautifully in the employee’s chat window, complete with clickable citations linking back to the original PDF.
All of this happens in less than 1.5 seconds.
Choosing the Right AI Stack for Your Needs
Architecture choices should be driven by scale, budget, data privacy, and engineering capacity.
- For Solo Creators & Startups: Speed to market is everything. Skip the massive infrastructure setup. Rely entirely on managed services. Use proprietary APIs (OpenAI/Anthropic), managed vector databases (Pinecone), and frameworks like CrewAI or Vercel AI SDK to get applications running instantly.
- For Mid-Market & Scaling Tech: You need flexibility to pivot and scale without drowning in API bills. A hybrid approach works best. Use open-source orchestration, host a reliable vector database, and build an “API Gateway” that allows you to hot-swap between proprietary models and cheaper open-weights models depending on the task complexity.
- For Enterprises (Finance, Healthcare, Defense): Security and IP protection are the absolute priorities. You require full control over Layer 1 and 2. This means investing in private, on-premises AI infrastructure (like Alibaba AI Stack or AWS Outposts), deeply fine-tuning open-source models on internal data, heavily utilizing Graph RAG for accuracy, and deploying aggressive FinOps and Guardrail layers.
Emerging Trends in the AI Stack for 2026
As we move deeper into the AI era, several profound trends are reshaping this architecture:
- The Shift from Orchestration to Agency: We are moving away from single prompt chatbots toward multi-agent ecosystems. Software will not just draft an email; a crew of autonomous agents will research the client, draft the copy, review it against brand guidelines, and schedule the delivery—all communicating with each other in the background.
- Multimodal RAG Pipelines: Modern RAG is moving far beyond text. Enterprises are embedding image vectors, video frames, and audio snippets. You will soon search your database by saying, “Show me the exact moment in the Q3 meeting video where the CEO drew the new architecture on the whiteboard.”
- Real-Time Streaming AI: Traditional ETL pipelines that update nightly are too slow. AI stacks are integrating streaming data technologies (like Apache Kafka) to allow models to reason over real-time events, such as livestock market fluctuations or immediate cybersecurity threat streams.
- On-Device AI and Edge Compute: Small Language Models (SLMs) will increasingly run directly on the Neural Processing Units (NPUs) of consumer laptops and smartphones. This allows for zero-latency, highly private AI execution for everyday tasks, only pinging up the expensive cloud layers for heavy analytical lifting.
- The AI Operating System: The lines between the OS and the AI application layer are blurring. Future interfaces won’t just be chatting windows open; the AI will sit at the system level, capable of observing your screen, moving your mouse, and natively interacting with traditional legacy software via GUI automation.
What matters
The transition to AI-native software is as fundamental as the transition from the command line to the graphical user interface, or from desktop to mobile. While the specific chips, models, and vendor names will inevitably evolve, the structural layers of the AI stack—how we compute, how we manage memory, how we retrieve context, and how we orchestrate logic—are firmly established.
For businesses and developers, understanding this full stack is the ultimate strategic advantage. Those who understand how to efficiently route queries, eliminate hallucinations through Advanced RAG, and orchestrate reliable autonomous agents will build the definitive software of the next decade. Master the stack, and you master the future of computation.




{kind=link}